AI 인프라의 핵심, RoCE vs InfiniBand 완벽 비교: 800Gbps 시대의 선택은?
AI GPU 인프라 도입시 인프라 성능의 핵심인 시스템 내부 네트워크 선택에 대해서 고민을 하게됩니다. AI(인공지능) 모델의 크기가 커짐에 따라 이를 뒷받침하는 네트워크 인프라의 중요성이 그 어느 때보다 강조되고 있습니다. 특히 GPU 간의 초고속 데이터 전송을 가능하게 하는 RDMA(Remote Direct Memory Access) 기술은 현대 AI 데이터센터의 필수 요소입니다.
오늘 포스팅에서는 최근 주목받고 있는 RoCE(RDMA over Converged Ethernet)의 최대 속도와 스펙, 그리고 영원한 라이벌인 InfiniBand(인피니밴드)와의 차이점 및 도입 비용까지 상세히 분석해 보겠습니다.
RoCE vs InfiniBand
1. RoCE 속도의 한계는 어디까지인가? (최대 800Gbps 지원 여부)
많은 분이 궁금해하시는 점이 “이더넷 기반의 RoCE가 과연 AI 인프라에서 요구하는 800Gbps 속도를 지원하는가?”입니다.
결론부터 말씀드리면, 네. 가능합니다.
2026년 기준 RoCE 속도 스펙
현재 AI 인프라 시장에서 RoCEv2는 물리적 이더넷 규격의 발전에 발맞추어 비약적인 속도 향상을 이루었습니다.
800Gbps 상용화: 현재 Broadcom Tomahawk 5 또는 NVIDIA Spectrum-4와 같은 고성능 스위치 칩셋을 통해 포트당 800Gbps 속도를 공식 지원합니다. 이는 대규모 GPU 클러스터에서 백본 네트워크로 이미 채택되고 있는 스펙입니다.
400Gbps 대중화: 현재 가장 널리 사용되는 규격으로, NVIDIA H100이나 B200 기반 서버의 NIC(네트워크 카드)에서 표준처럼 쓰이고 있습니다.
1.6Tbps(1600Gbps) 로드맵: IEEE 802.3dj 표준을 기반으로 한 1.6T 이더넷이 기술 검증 단계를 지나 초기 도입 단계에 진입해 있습니다.
Exadata X11M의 사례: 참고로 오라클의 최신 엔지니어드 시스템인 Exadata X11M의 경우, 내부 스토리지와 서버 구간에 100Gbps RoCE를 사용하며, 듀얼 포트 구성을 통해 서버당 총 200Gbps의 대역폭을 제공하여 DB 처리 효율을 극대화하고 있습니다.
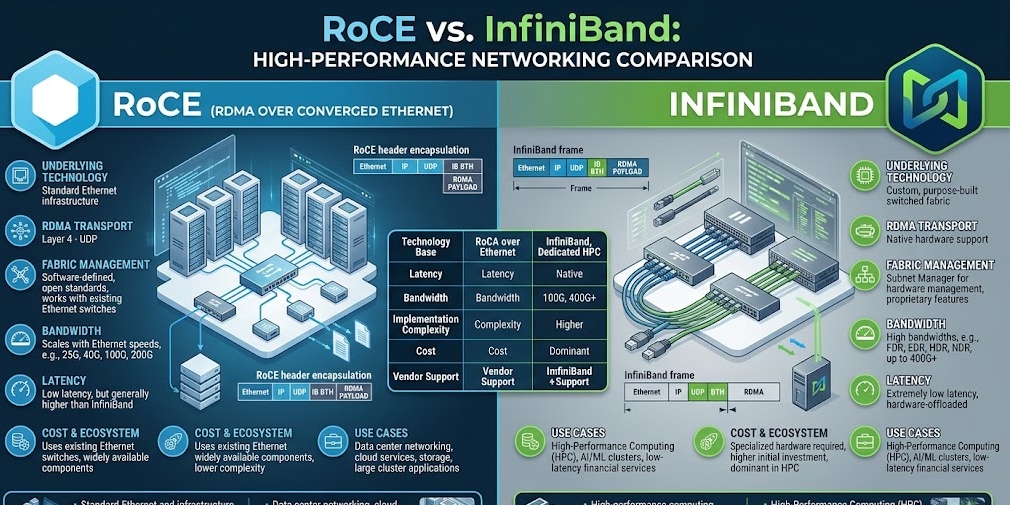
2. InfiniBand vs RoCE: 기술적 차이점 분석
두 기술 모두 CPU를 거치지 않고 메모리에 직접 접근하는 RDMA 기술을 공유하지만, 구현 방식에는 큰 차이가 있습니다.
InfiniBand: HPC를 위한 전용 트랙
인피니밴드는 처음부터 고성능 컴퓨팅(HPC)을 위해 설계된 전용 아키텍처입니다.
무손실(Lossless) 네트워크: 하드웨어 수준에서 흐름 제어(Flow Control)를 수행하여 패킷 손실이 거의 없습니다.
초저지연: 프로토콜 오버헤드가 극히 적어 지연 시간(Latency)이 매우 짧고 일정합니다.
RoCE: 개조된 고속도로
RoCE는 범용적인 이더넷(Ethernet) 환경 위에서 RDMA를 구현한 것입니다.
친숙한 인프라: 기존 이더넷 스위치와 관리 도구를 그대로 사용할 수 있습니다.
설정의 복잡성: 이더넷은 본래 패킷 손실을 허용하는 구조이기 때문에, RoCE를 제대로 쓰려면 PFC(Priority Flow Control)나 ECN(Explicit Congestion Notification) 같은 복잡한 무손실 설정을 수동으로 해줘야 합니다.
3. 도입 비용 비교: 얼마나 차이 날까?
기업 입장에서 가장 중요한 것은 역시 비용(TCO)입니다. 일반적으로 RoCE(이더넷) 기반 인프라는 InfiniBand보다 경제적입니다.
비용 차이 요약 (Percentage)
업계 추산에 따르면, 동일 대역폭 기준 네트워크 구축 비용은 다음과 같습니다.
CAPEX(장비 도입비): RoCE 도입 시 InfiniBand 대비 약 30% ~ 50% 절감 가능.
스위치 단가: 이더넷 스위치는 인피니밴드 전용 스위치보다 최대 50% 저렴하게 형성되기도 합니다.
OPEX(운영비): 기존 네트워크 엔지니어가 이더넷 관리 도구로 운영할 수 있어 인력 교육 및 유지보수 비용이 낮습니다.
왜 RoCE가 더 저렴할까요?
이더넷은 전 세계 표준으로 공급업체가 다양하여 가격 경쟁이 치열한 반면, 인피니밴드는 특정 제조사의 독점적 지위가 강하기 때문입니다.
4. NVIDIA의 인피니밴드 독점, 그 의미는?
현재 “InfiniBand는 NVIDIA가 독점하고 있다”는 말은 시장의 불편한 진실입니다.
Mellanox 인수: NVIDIA는 인피니밴드 시장의 1위 기업인 멜라녹스를 인수하며 하드웨어 공급권을 완전히 장악했습니다.
수직 계열화: GPU(H100/B200)와 인피니밴드(Quantum 스위치), 전용 소프트웨어(NCCL)를 하나의 패키지로 묶어 최적화했습니다. 다른 네트워크를 쓰면 성능이 떨어질 수 있다는 우려를 가지게 만들어 ‘락인(Lock-in) 효과’를 극대화한 것이죠.
가격 결정권: 경쟁자가 없기에 NVIDIA가 높은 가격을 유지하더라도 대안을 찾기가 쉽지 않습니다.
이러한 독점에 대응하기 위해 최근 Google, Meta, AMD 등은 Ultra Ethernet Consortium(UEC)을 결성하여 이더넷 기반 AI 네트워크 표준화를 서두르고 있습니다.
AI network
5. 결론: 우리 기업에 최적인 네트워크 선택 전략
AI 인프라를 구축할 때 InfiniBand와 RoCE(Ethernet) 중 무엇을 선택하느냐는 단순한 속도 비교를 넘어, 기업의 비즈니스 전략과 운영 역량, 그리고 예산 효율성을 결정짓는 핵심적인 의사결정입니다. 두 기술의 지향점이 명확한 만큼, 우리 기업의 상황에 대입해 최적의 선택안을 정리해 드립니다.
CASE 1. InfiniBand를 선택해야 하는 경우: “성능이 곧 경쟁력인 곳”
만약 기업의 핵심 비즈니스가 초거대 언어 모델(LLM)의 사전 학습(Pre-training)이나 복잡한 과학 계산용 슈퍼컴퓨팅에 있다면, 망설임 없이 InfiniBand를 선택해야 합니다.
성능의 일관성(Tail Latency): 수천 개의 GPU가 동시에 데이터를 주고받는 ‘All-Reduce’ 작업 시, 단 하나의 노드라도 지연이 발생하면 전체 학습 속도가 저하됩니다. InfiniBand는 하드웨어 기반의 혼잡 제어를 통해 지연 시간의 변동폭을 최소화하여 학습 효율을 극대화합니다.
플러그 앤 플레이(Plug & Play) 최적화: NVIDIA의 인프라(DGX 서버 등)를 도입할 경우, InfiniBand는 별도의 복잡한 네트워크 튜닝 없이도 즉시 최상의 성능을 내도록 최적화되어 있습니다. 구축 기간을 단축하고 시행착오를 줄여야 하는 긴박한 AI 경쟁 환경에서 큰 강점이 됩니다.
추천 타겟: 자체 거대 모델을 보유한 빅테크 기업, 국가 주도 슈퍼컴퓨팅 센터, 대규모 GPU 팜(Farm)을 운영하는 AI 전문 스타트업.
CASE 2. RoCE(Ethernet)를 선택해야 하는 경우: “유연성과 가성비의 조화”
반면, 이미 탄탄한 이더넷 인프라를 갖추고 있으며 실질적인 서비스 운영(Inference)이나 특화된 엔터프라이즈 AI 구축이 목표라면 RoCE가 훨씬 현명한 선택입니다.
압도적인 비용 효율성(TCO): 앞서 언급했듯이 RoCE 기반 이더넷 장비는 InfiniBand 대비 구축 비용을 30~50% 이상 절감할 수 있습니다. 한정된 예산으로 더 많은 GPU 자원을 확보해야 하는 기업에게는 최고의 대안입니다.
운영의 연속성: 새로운 인피니밴드 전문가를 채용할 필요 없이, 기존의 네트워크 운영팀이 익숙한 도구와 방식으로 관리할 수 있습니다. 이는 장기적인 유지보수 측면에서 매우 큰 이점입니다.
확장성과 범용성: RoCE는 표준 이더넷 기술을 따르기 때문에 특정 제조사에 종속되지 않습니다. 기술 로드맵에 따라 다양한 제조사의 스위치와 NIC를 혼용할 수 있어 공급망 리스크(Shortage) 대응에도 유리합니다.
추천 타겟: 금융·의료 등 보안이 중요한 프라이빗 AI 클라우드 구축 기업, AI 모델 추론 서비스를 제공하는 기업, 이더넷 기반의 데이터센터를 확장하려는 엔터프라이즈.
최종 제언: 하이브리드 전략도 고려하라
최근에는 학습(Training) 구간에는 InfiniBand를, 추론(Inference) 및 스토리지 연결 구간에는 RoCE를 사용하는 하이브리드 구성이 대세로 자리 잡고 있습니다.
800Gbps라는 압도적인 대역폭이 양쪽 진영 모두에서 구현된 만큼, 이제는 단순히 ‘누가 더 빠른가’의 문제가 아니라 ‘누가 우리 기업의 운영 환경에 더 잘 녹아드는가’ 를 따져봐야 합니다. 기술적 성능 수치에 매몰되기보다, 비즈니스의 목적과 인적 자원, 그리고 예산의 균형점을 찾는 것이 성공적인 AI 인프라 구축의 첫걸음입니다.