Physical Address
South Korea
Physical Address
South Korea
"엔터프라이즈 IT 인프라 및 클라우드 트러블슈팅 가이드"
"엔터프라이즈 IT 인프라 및 클라우드 트러블슈팅 가이드"

엔터프라이즈 환경에서 인프라를 운영하다 보면 누구나 한 번쯤 “서버가 왜 이렇게 느리죠?”라는 날카로운 질문을 받게 됩니다. 특히 Oracle ExaCC 같은 고성능 통합 플랫폼이나 대규모 클라우드 환경을 다룰 때는 식은땀이 절로 납니다. 아주 작은 병목 지점 하나가 서비스 전체를 마비시키는 ‘나비효과’를 현장에서 수없이 목격했기 때문입니다.
예전에는 장애가 터지면 화려한 대시보드부터 켜고 멍하니 쳐다보곤 했습니다. 하지만 수년간 밤을 새우며 장애 분석을 해보니, 진짜 중요한 건 모니터링 툴의 화려함이 아니었습니다. 수많은 데이터 중 ‘지금 진짜 문제가 되는 지표’를 선별하고, 그들 간의 상관관계를 읽어내는 눈이 핵심이었습니다.
단순히 CPU 사용률이 높다고 서버 사양을 올리던 시대는 끝났습니다. 시스템의 물리적 자원(OS)과 그 위에서 돌아가는 워크로드(DB)가 어떻게 연결되어 있는지 모르면 밑 빠진 독에 물 붓기가 되기 십상입니다. 오늘은 제가 현장에서 구르며 깨달은, 반드시 챙겨야 할 핵심 지표와 현대적인 모니터링 솔루션 활용 전략을 가감 없이 공유해 드립니다.
OS 모니터링은 시스템의 기초 체력을 보는 단계입니다. 장애가 나면 가장 먼저 열어보는 곳이지만, 단순히 “숫자가 낮으니 괜찮네” 하고 넘어가면 진짜 폭탄을 놓치게 됩니다. 우리는 수치 자체가 아니라 대기 큐(Queue)와 지연 시간(Latency)의 미세한 변화를 포착해야 합니다.
많은 인프라 관리자가 CPU 사용률(Utilization)이 70% 미만이면 시스템이 아주 안정적이라고 안심합니다. 저 역시 초년생 시절엔 그랬습니다. 하지만 실제 사용자가 체감하는 응답 속도를 결정짓는 진짜 범인은 따로 있었습니다.
💡 실무자를 위한 관리 기준 요약
- Utilization (CPU 연산량): 70~80% 수준으로 유지하는 것이 마음 편합니다.
- Load Average (대기 프로세스): 무조건 CPU 코어 수 미만으로 떨어뜨려 놔야 안전합니다.
- CPU Steal (자원 손실): 클라우드 기준 1~3% 미만이어야 이웃을 잘 만난 것입니다.
리눅스 서버를 처음 관리하시는 분들이 가장 많이 하는 실수가 “free 메모리가 0에 가까워요! 서버 터지기 직전입니다!”라며 밤중에 전화를 거는 것입니다. 결론부터 말씀드리면, 리눅스 세계에서 “놀고 있는 Free 메모리는 낭비”입니다.
리눅스 커널은 똑똑해서 디스크 I/O 속도를 높이기 위해 남는 메모리를 ‘페이지 캐시(Page Cache)’와 ‘버퍼(Buffer)’로 꽉꽉 채워 씁니다. 자주 쓰는 데이터를 미리 메모리에 올려두는 것이죠. 따라서 free 영역이 적더라도 buff/cache 영역이 넉넉하다면 시스템이 일을 아주 잘하고 있다는 뜻입니다.
우리가 진짜 소름 돋아야 할 때는 vmstat을 쳤을 때 si(Swap In)와 so(Swap Out)가 찍힐 때입니다.
물리 메모리(RAM)가 부족해지면 커널은 디스크의 일부 공간(Swap)을 메모리처럼 빌려 씁니다. 하지만 디스크는 RAM보다 백 배 이상 느립니다. 데이터가 이 스왑 영역을 오가기 시작(Paging)하면, 디스크 I/O가 폭발하면서 사이트 응답 속도가 눈에 띄게 처참해집니다.
만약 이 페이징 현상을 방치하면 커널은 시스템 전체가 죽는 걸 막기 위해 가장 메모리를 많이 먹는 프로세스를 강제로 사형시킵니다. 이게 바로 악명 높은 OOM(Out Of Memory) Killer입니다. 아침에 출근했는데 DB나 WAS 프로세스가 의문사해 있다면, 높은 확률로 이 녀석 소관입니다. 평소에 /var/log/syslog나 dmesg를 통해 OOM 로그를 실시간으로 감시해야 하는 이유가 바로 여기에 있습니다.
요즘처럼 성능 좋은 SSD나 NVMe 스토리지를 쓰는 환경에서는 “얼마나 많은 양을 전송하느냐(Throughput)”보다 “얼마나 빨리 응답하느냐(Await 지연 시간)”가 훨씬 중요합니다. iostat 명령어를 실행했을 때 %util이 100%를 찍더라도 실제 스토리지의 대역폭은 남아있는 경우가 많으니, 늘 await(I/O 요청 처리 평균 시간)이 5ms를 넘지 않는지 체킹하는 습관이 필요합니다.
데이터베이스 모니터링은 OS보다 차원이 다르게 복잡합니다. OS 대시보드는 CPU 10%, 메모리 여유로움으로 평온해 보이는데, 실제 서비스는 멈춰버리는 기현상이 자주 일어납니다. DB 내부에서 ‘락(Lock)’이 걸렸거나 자원 경합이 벌어졌을 때 이런 일이 생깁니다.
DB 성능 저하의 90% 이상은 무언가를 기다리는 ‘대기’에서 시작됩니다. 특히 Oracle 환경을 기준으로 아래 세 가지 이벤트는 외워두시는 게 좋습니다.
새로운 SQL문이 들어올 때마다 이를 분석하고 실행 계획을 짜는 과정을 ‘파싱’이라고 합니다. 이 과정이 반복되면 CPU 점유율이 미친 듯이 솟구칩니다. Shared Pool과 Library Cache 적중률을 모니터링하면서, 바인드 변수를 적절히 사용해 이미 짜여진 실행 계획을 재사용하고 있는지 체크해야 합니다.
성능 문제는 결코 하나의 지표만 보고 파악할 수 없습니다. OS와 DB의 지표를 결합해서 보는 ‘입체적인 시각’이 필요합니다.
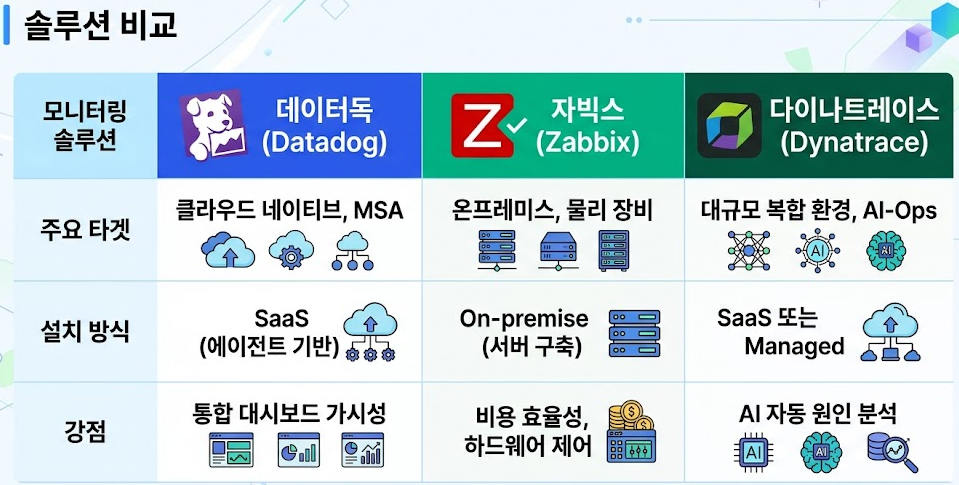
db file parallel read 대기가 치솟고 있다면, 곧바로 OS 레벨의 iostat을 확인해야 합니다. 만약 OS에서도 디스크 대기 시간(await)이 함께 늘어났다면 물리 디스크나 스토리지 네트워크(SAN)의 선로 혼잡일 가능성이 큽니다. 반대로 OS는 멀쩡한데 DB만 대기가 높다면 DB 내부 파라미터 튜닝의 영역입니다.이 방대한 지표들을 매번 명령어 쳐가며 볼 수는 없겠죠. 엔터프라이즈 실무에서 가장 선호되는 솔루션 3가지의 특징과 제 경험을 섞어 정리해 드립니다.
SaaS 기반 모니터링의 최강자입니다. 특히 마이크로서비스 아키텍처(MSA)나 클라우드 네이티브 환경에서 빛을 발합니다.
폐쇄망 환경이나 엔터프라이즈의 무거운 물리 하드웨어, 네트워크 장비를 감시할 때 이만한 툴이 없습니다. 오픈소스라 비용 효율성도 극상입니다.
대규모 하이브리드 클라우드를 운영하는 대기업에서 가장 탐내는 툴입니다. AI 엔진인 Davis®가 탑재되어 있어 운영자의 피로도를 획기적으로 줄여줍니다.
Smartscape 기능이 인프라 구성 요소 간의 복잡한 의존 관계를 자동으로 지도로 그려줍니다. 장애가 터지면 수백 개의 알람을 보내는 게 아니라, 딱 하나의 근본 원인 알람을 보냅니다. *”현재 가입 서비스가 지연되는 원인은 B 호스트의 메모리 스왑 발생 때문입니다”*라고 명쾌하게 답을 줍니다. 비용은 비싸지만 값어치를 합니다.| 분류 | 데이터독 (Datadog) | 자빅스 (Zabbix) | 다이나트레이스 (Dynatrace) |
| 주요 타겟 | 클라우드 네이티브, MSA, 스타트업 | 온프레미스, 물리 장비, 전통 기업 | 대규모 복합 인프라, 금융권, 금융 대기업 |
| 설치 방식 | SaaS (에이전트 기반형) | On-premise (자체 서버 구축형) | SaaS 또는 Managed 선택 가능 |
| 최대 강점 | 트렌디한 UI, 유기적인 APM 연동 | 라이선스 비용 제로, 강력한 커스텀 | AI 기반 장애 근본 원인 자동 분석 |
이제 단순히 특정 임계치(예: CPU 80%)를 넘기면 문자나 슬랙으로 알람을 던져주는 방식은 구식이 되었습니다. 머신러닝이 알아서 평소 트래픽 패턴을 학습하고, 평일 이 시간에 나올 수 없는 이상 징후(Anomaly)가 포착될 때만 스마트하게 알려주는 시대입니다.
하지만 아무리 도구가 똑똑해져도 결국 최종 의사결정을 내리고 시스템 구조를 개선하는 것은 엔지니어의 통찰력입니다. “메모리 점유율이 80%네?” 하고 넘기지 마십시오. 그 뒤에 숨겨진 페이징 활동량과 DB 대기 이벤트를 엮어서 서비스의 흐름을 읽을 줄 알아야 진정한 솔루션 아키텍트가 될 수 있습니다.
오늘 글을 닫으면서 한 가지만 제안해 드립니다. 지금 바로 운영 중인 서버에 접속하셔서 Swap In/Out 수치를 확인해 보세요. 그리고 여러분의 모니터링 알람이 단순한 ‘생존 신고’ 수준에 머물러 있지는 않은지 재점검해 보시기 바랍니다. 작은 지표 하나를 꼼꼼히 챙기는 습관이, 새벽에 걸려 오는 장애 전화를 막아줄 유일한 방패입니다.
[RHEL 9.6 기반 톰캣(Tomcat) 설치 및 최적화 운영 전략: 임베디드 vs 독립형]