Physical Address
South Korea
Physical Address
South Korea
"엔터프라이즈 IT 인프라 및 클라우드 트러블슈팅 가이드"
"엔터프라이즈 IT 인프라 및 클라우드 트러블슈팅 가이드"
인프라 엔지니어로 일하면서 가장 가슴이 철렁하는 순간이 언제일까요? 새벽에 울리는 모니터링 알람도 무섭지만, 경영진이나 고객사로부터 “비즈니스 연속성 계획(BCP) 수립을 위한 재해 복구(DR) 시스템 구축 제안서”를 가져오라는 요청을 받을 때가 참 난감합니다.
과거에 겪었던 대형 데이터 센터 화재 사건이나 예기치 못한 해킹 시도 같은 끔찍한 기억들이 스쳐 지나가기 때문이죠.
실무자 입장에서 DR 구축은 참 무거운 숙제입니다.
“장애가 나도 서비스가 안 끊기게 완벽하게 이중화해 주세요.”
“그런데 예산은 최소한으로 맞춰주셔야 합니다.”
미팅룸에서 흔히 듣는 말이지만, 현실은 냉정합니다. 인프라를 완벽하게 똑같이 복제하자니 비용이 천문학적으로 치솟고, 비용을 아끼려고 대충 구성하자니 “나중에 장애 터지면 누가 책임질 거냐”는 무서운 질문이 돌아옵니다.
결국 DR 구축의 본질은 기술 자랑이 아니라, 회사가 감당할 수 있는 리스크와 비용 사이의 타협점(Trade-off)을 찾는 일입니다.
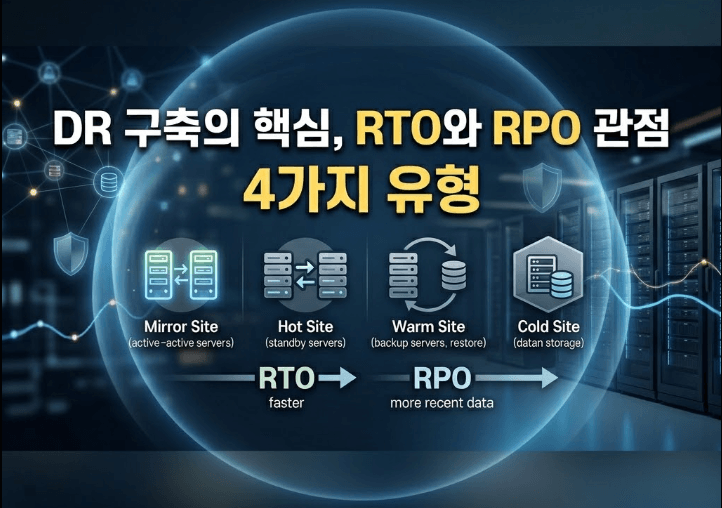
오늘은 제가 수많은 시행착오를 겪으며 정리한 재해 복구 시스템의 4가지 핵심 유형(Mirror, Hot, Warm, Cold)을 실무자 관점에서 가감 없이 풀어보려 합니다. 인프라 도입을 고민하는 의사결정자나 동료 엔지니어분들에게 현실적인 가이드가 되길 바랍니다.
DR 이야기를 시작할 때 이 두 가지 약어를 빼놓을 수 없습니다. 미팅룸에서 “비용은 아끼고 100% 복구되게 해달라”는 무리한 요구를 받을 때, 우리는 이 지표를 꺼내 들어야 합니다. 기술의 세계에서 비용과 복구 성능은 정확히 비례하거든요.
엔지니어로서 강조하고 싶은 팩트는 하나입니다. RTO와 RPO를 제로(0)에 가깝게 낮출수록, 회사가 지불해야 하는 인프라 비용은 기하급수적으로 증가합니다. 이 냉정한 현실을 인정해야만 우리 기업에 맞는 진짜 아키텍처를 그릴 수 있습니다.
이제 본격적으로 4가지 유형을 살펴보겠습니다. 장점만 나열한 제안서 양식이 아니라, 실무에서 마주치는 명과 암을 솔직하게 짚어보겠습니다.
주 센터(Primary)와 똑같은 쌍둥이 데이터 센터를 원격지에 하나 더 지어두고, 양쪽을 동시에 가동하는 방식입니다.
실무 엔지니어의 속마음 (Pros & Cons)
- 장점: 엔지니어가 새벽에 인프라 터졌다고 허겁지겁 노트북을 켤 필요가 없습니다. 시스템이 알아서 트래픽을 돌려주니까요. 글로벌 서비스나 대형 금융 결제망에서는 필수입니다.
- 단점: 돈이 정확히 2배 이상 듭니다. 더 무서운 건 **’네트워크 지연(Latency)’**입니다. 실시간으로 데이터를 동기화해야 하기 때문에 두 센터 거리가 멀면 패킷 왕복 시간 때문에 주 센터 서비스까지 느려집니다. 그래서 보통 40km~100km 이내에 짓는데, 이러면 수도권 전체에 대형 정전이 났을 때 두 센터가 동시에 죽는 모순이 발생합니다.
주 센터와 거의 같은 장비들을 원격지에 켜두고(Standby), 데이터를 실시간에 가깝게 복제하는 방식입니다.
실무 엔지니어의 속마음 (Pros & Cons)
- 장점: 거리에 제약이 없습니다. 서울 주 센터 – 부산 DR 센터 구성이 가능해서 국지적 재난에서 안전합니다. 국내 은행이나 대형 쇼핑몰이 가장 선호하는 현실적인 최선책입니다.
- 단점: 평소에 쓰지도 않는 대기 장비와 소프트웨어 라이선스 비용이 매달 꼬박꼬박 나갑니다. “왜 놀고 있는 장비에 수천만 원씩 쓰냐”는 경영진의 압박을 방어하기 위해, 평소에는 이 대기 장비들을 개발 테스트 환경이나 대규모 데이터 분석용으로 슬쩍 돌려쓰는 ‘아키텍처적 잔머리’가 필요합니다.
중요한 장비만 몇 대 사두거나, 장비는 있되 운영체제(OS)나 최종 데이터가 완벽하게 세팅되지 않은 채로 대기하는 형태입니다.
실무 엔지니어의 속마음 (Pros & Cons)
- 장점: 비용이 확 줍니다. 비싼 실시간 동기화 솔루션 값을 안 내도 되니 중견기업의 ERP 시스템 등에서 애용합니다.
- 단점: 진짜 재해가 터지면 엔지니어들의 피와 땀, 눈물로 시동을 걸어야 합니다. 장비 전원 켜고, OS 확인하고, 백업 테이프나 스토리지에서 데이터를 하나하나 부어야(Restore) 합니다. 평소에 복구 매뉴얼을 제대로 안 만들어 뒀다면, 복구 도중에 에러가 나서 수 일이 걸릴 작업이 수 주일로 늘어나는 대참사가 벌어집니다. 데이터가 날아간 하루 동안의 공백은 현업 부서 직원들이 엑셀을 보며 수작업으로 메워야 하는 지옥문이 열립니다.
평소에는 데이터 센터의 빈 공간(랙 스페이스, 전력 등)만 계약해 두고, 장비는 아예 없거나 꺼져 있는 상태입니다.
실무 엔지니어의 속마음 (Pros & Cons)
- 장점: 가성비 끝판왕입니다. 평소에 나가는 고정비가 거의 없습니다.
- 단점: 사실 현대적인 IT 서비스 기업에서는 고르면 안 되는 옵션입니다. 재해 나서 서버 새로 주문하고, 입고 받아서 케이블 연결하고 처음부터 빌드하다 보면 이미 경쟁사로 고객들이 다 떠나고 회사가 망해있을 확률이 높습니다. 요즘은 법적 규제 때문에 데이터를 10년 이상 의무 보관해야 하는 ‘장기 아카이빙’ 용도로만 씁니다.
복잡한 내용을 실무 회의나 보고서에 바로 써먹을 수 있게 한눈에 볼 수 있는 표로 정리했습니다.
| 구분 | Mirror Site (즉시 복구) | Hot Site (고가용성) | Warm Site (중간 단계) | Cold Site (데이터 중심) |
| RTO (복구 시간) | 즉시 (0에 수렴) | 수 시간 이내 (보통 4시간) | 수 일 이내 | 수 주 ~ 수 개월 이상 |
| RPO (복구 시점) | 데이터 손실 없음 (0) | 거의 없음 (수 분 이내) | 수 시간 ~ 수 일 전 | 수 일 ~ 수 주 전 |
| 비용 규모 | 매우 높음 (인프라 2배) | 높음 (상시 대기 장비) | 보통 (백업 장비 중심) | 매우 낮음 (공간만 임대) |
| 데이터 상태 | 실시간 동기화 | 실시간에 가까운 비동기 | 주기적 백업본 전송 | 오프라인 백업 (테이프 등) |
| 추천 대상 서비스 | 글로벌 결제, 핵심 인증망 | 대형 이커머스, 은행 | 일반 업무 시스템, ERP | 장기 보존용 데이터 백업 |
제가 RFP를 들고 온 고객사 미팅에서 가장 먼저 던진 한마디는 이것이었습니다.
“모든 시스템을 Mirror나 Hot Site로 만들려고 하지 마세요. 회사가 파산합니다.”
정답은 ‘서비스 등급화(Tiering)’에 있습니다. 중요도에 따라 인프라를 쪼개야 돈을 아낍니다.
과거처럼 데이터 센터에 무식하게 장비를 두 배로 사서 쟁여두는 시대는 지났습니다. AWS, Azure, GCP 같은 퍼블릭 클라우드가 발전하면서 DR 구축 패러다임이 완전히 바뀌었죠. 클라우드를 쓰면 Warm Site 비용으로 Hot Site 급 성능을 낼 수 있습니다.
평소에는 가스레인지의 작은 불꽃(Pilot Light)처럼 데이터베이스만 실시간으로 복제해 두고, 애플리케이션 서버들은 이미지 형태로 꺼둡니다. 그러다 재해가 터지면 테라폼(Terraform) 같은 코드로 수 분 만에 수십, 수백 대의 서버를 클라우드 위에 즉시 가동(프로비저닝)시키는 방식입니다. 돈은 적게 드는데 복구는 엄청나게 빠릅니다.
지금 시점에 DR 구축을 새로 검토하신다면, 장비를 또 구매하는 방식은 멈추셔야 합니다. 설령 회사의 본 시스템이 자체 전산실(온프레미스)에 있더라도, 재해 복구 센터만큼은 클라우드로 구성하는 하이브리드 Cloud DR이 가장 가성비 좋은 대안입니다.
DR(재해 복구) 시스템은 일종의 ‘자동차 보험’과 같습니다. 사고가 나지 않을 때는 매달 생돈이 나가는 것 같아 아깝지만, 대형 사고가 터지는 순간 회사의 생존을 결정짓는 유일한 생명줄이 됩니다.
가장 비싼 DR이 무조건 좋은 게 아닙니다. 우리 회사의 비즈니스가 멈췄을 때 발생하는 손해 비용을 냉정하게 계산하고, 그 금액에 맞춰 밸런스를 잡은 DR이 최고의 DR입니다. 여러분의 서비스는 지금 어떤 등급의 보험이 필요하신가요?
[비즈니스 연속성을 위한 DR 구축 시나리오와 데이터 동기화 기술]