Physical Address
South Korea
Physical Address
South Korea
"엔터프라이즈 IT 인프라 및 클라우드 트러블슈팅 가이드"
"엔터프라이즈 IT 인프라 및 클라우드 트러블슈팅 가이드"
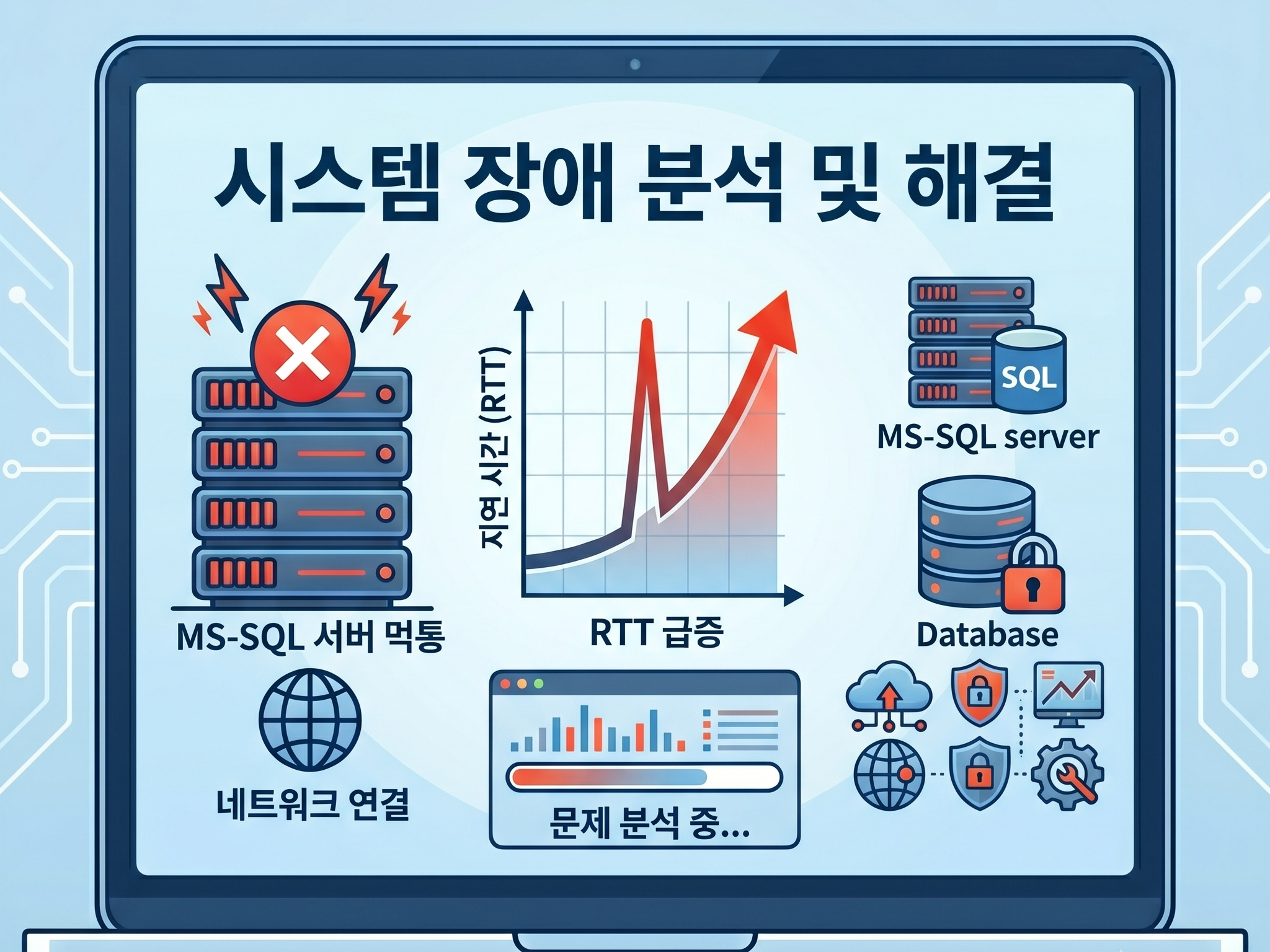
서버를 관리하면서 가장 등골이 오싹해지는 순간이 언제일까요? 제 경험상, CPU나 메모리 사용률은 10%대에서 평온하게 노고 있는데, 실제 서비스는 완전히 먹통이 되고 심지어 서버에 핑(Ping)조차 나가지 않는 상황입니다.
“하드웨어 자원이 이렇게 남아도는데 왜 서버가 응답을 안 하지?”
특히 회사의 핵심 데이터베이스인 MS-SQL 서버에서 이런 현상이 터지면 그야말로 멘붕에 빠지게 됩니다. 원인을 못 찾아 애꿎은 네트워크 회선만 탓하거나 서버를 엄한 타이밍에 재부팅 하기도 하죠. 하지만 진짜 범인은 눈에 보이는 하드웨어 수치 너머, OS 커널 모드의 정체와 보안 솔루션의 I/O 충돌인 경우가 많습니다.
오늘은 제가 실제 데이터독(Datadog) 모니터링을 통해, DB 접근 제어 솔루션인 샤크라맥스(ChakraMax) 환경에서 발생했던 디스크 쓰기 지연과 네트워크 마비의 끈질긴 악연을 어떻게 풀어냈는지 그 실전 경험을 공유해 보려고 합니다.
어느 날 갑자기 알람이 울립니다. 네트워크 응답 시간인 RTT(Round Trip Time)가 평소보다 수십 배인 수백 ms로 치솟더니, 이내 Request Timed Out 메시지와 함께 서버가 외딴섬이 되어버렸습니다.
처음에는 단순히 네트워크 장비나 회선 문제인 줄 알았습니다. 하지만 서버 내부를 들여다보니 CPU는 너무나도 한가했습니다. 연산 자원이 남는데 네트워크가 끊기는 이 미스터리를 풀려면, Windows Server의 커널(Kernel) 구조를 이해해야 합니다.
Windows 환경에서 네트워크 패킷을 처리하는 ‘네트워크 스택’과 데이터를 하드디스크에 저장하는 ‘I/O 스택’은 몸통이 같습니다. 모두 ‘커널’이라는 핵심 자원을 공유하죠. 문제는 여기서 발생합니다. 특정 보안 에이전트의 간섭 때문에 디스크 쓰기 작업(Write I/O)이 아주 미세하게 지연되면, OS 커널은 이 I/O 처리가 끝날 때까지 손가락을 빨며 대기 상태(Wait State)에 빠지게 됩니다.
이때 가장 치명적인 게 바로 인터럽트(Interrupt) 처리 우선순위입니다. 외부에서 들어오는 핑(ICMP) 요청은 커널이 즉각적으로 반응해 줘야 하는 인터럽트 작업입니다. 하지만 커널이 디스크 쓰기 응답 지연 때문에 ‘I/O 완료 대기’라는 늪에 빠져버리면, 네트워크 인터럽트 처리는 뒤로 밀리거나 완전히 씹히게 됩니다.
결과적으로 CPU는 할 일이 없어 쉬고 있는 것처럼 보이지만, 시스템의 심장부인 커널이 묶여서 외부 통신 창구를 닫아버리는 ‘소프트웨어적 교착 상태’가 되는 것입니다.
그렇다면 왜 디스크 쓰기 지연이 발생했을까요? 범인은 보안을 위해 설치해 둔 데이터베이스 접근 제어 솔루션, ‘샤크라맥스’였습니다.
샤크라맥스는 안정을 위해 서버로 들어오는 모든 쿼리를 가로채고(Interception), 이에 대한 방대한 감사 로그(Audit Log)를 남깁니다. 보안을 위해서는 필수적이지만, 이 과정에서 발생하는 디스크 쓰기가 MS-SQL 엔진과 부딪히면 엄청난 병목이 생깁니다.
여기서 우리가 꼭 알아야 할 핵심 개념이 있습니다. 바로 디스크 사용률(Utilization)과 응답 시간(Latency)의 차이입니다.
보통은 디스크가 바빠야 응답 시간도 늘어납니다. 그런데 데이터독 지표를 보니 “사용률은 5% 미만인데, 응답 시간은 수백 ms”라는 기이한 현상이 나타났습니다.
이건 물리적인 디스크 성능(하드웨어) 한계가 아니라, 데이터를 디스크로 전달하는 통로(필터 드라이버나 보안 에이전트)에서 누군가 꽉 막고 있다는 강력한 증거입니다.
샤크라맥스가 대량의 감사 로그를 기록하는 그 짧은 순간에 디스크 I/O 락(Lock)이 걸렸고, 이 때문에 MS-SQL의 트랜잭션 로그 쓰기 작업(WRITELOG)까지 줄줄이 소시지처럼 밀려버린 것입니다. 하드웨어는 여유롭지만 소프트웨어 레이어의 통제 때문에 시스템 전체가 마비되는 전형적인 패턴이었습니다.
말만 해서는 인프라 팀이나 보안 팀을 설득할 수 없습니다. 숫자로 증명해야 하죠. 제가 데이터독에서 범인을 지목할 때 활용한 3단계 점검 경로입니다. 그대로 따라가 보시면 대략적인 답이 나옵니다.
Infrastructure -> Networktcp.retransmits (TCP 재전송)Infrastructure -> Hosts -> [대상 서버 선택] -> Disk 탭system.disk.write_time 및 system.disk.in_flightin_flight(현재 처리 중인 I/O 요청 수)는 수십 개로 치솟아 있는데, 정작 디스크 사용률(utilization)이 낮다면 커널 내부에 요청이 갇혀서 빠져나오지 못하는 심각한 커널 병목 상태를 의미합니다.Dashboards -> Microsoft SQL Server OverviewWRITELOG 대기 유형 (Wait Type)WRITELOG 대기 시간이 급증했다면, 샤크라맥스의 로그 기록 행위가 DB 엔진의 발목을 잡고 있다는 결정적 증거가 됩니다.이 문제를 근본적으로 해결하기 위해 제가 적용했고, 또 권장하는 실전 액션 플랜 4가지입니다.
가장 먼저 해야 할 일은 샤크라맥스가 쓰는 감사 로그 저장 경로와 MS-SQL의 데이터 파일(.mdf, .ldf) 드라이브를 물리적으로 완전히 찢어 놓는 것입니다. 같은 드라이브(혹은 같은 LUN)를 공유하면 디스크 헤더 경합과 쓰기 큐 정체가 무조건 생깁니다. 감사 로그 전용의 별도 디스크를 할당해 I/O 경로를 격리하세요.
보안 솔루션이 MS-SQL의 실시간 데이터 파일을 계속 감시하고 쿼리를 가로채면 응답 시간이 기하급수적으로 튑니다. MS-SQL이 사용하는 확장자(.mdf, .ldf, .ndf)는 물론이고, SQL Server 프로세스 자체(sqlservr.exe)를 보안 솔루션의 실시간 감시 및 백신 스캔 대상에서 반드시 제외해야 합니다.
고부하 상황에서 핑이 끊기는 걸 막으려면 네트워크 카드(NIC) 드라이버를 최신 제조사 버전으로 업데이트하는 것이 기본입니다. 추가로 고급 설정에서 RSS(Receive Side Scaling) 옵션을 활성화해 주세요. 하나의 CPU 코어가 네트워크 패킷을 독점 처리하다가 뻗는 걸 막고, 여러 코어가 병렬로 네트워크 인터럽트를 처리할 수 있게 해줍니다.
추후 모니터링을 위해 system.cpu.interrupt 지표를 대시보드에 올려두세요. 네트워크가 끊기는 시점에 커널 인터럽트 수치가 요동친다면 커널이 I/O 대기에 매몰되었다는 뜻입니다. 이 지표와 system.disk.write_time을 타임라인상에 겹쳐놓으면 장애 원인 지점을 아주 쉽게 고립시킬 수 있습니다.
인프라를 관리하다 보면 단순히 “CPU 점유율이 낮으니 안전하다”는 숫자의 함정에 빠지기 쉽습니다. 하지만 이번 사례처럼 연산 자원이 90% 이상 남아돌아도, 시스템의 신경망인 ‘커널 모드’가 묶여버리면 서버는 순식간에 식물인간 상태가 됩니다.
안정적인 서버 운영은 단순히 숫자의 높고 낮음을 보는 것이 아니라, 시스템 깊숙한 곳에서 유기적으로 움직이는 데이터의 흐름과 우선순위를 제어하는 것에서 시작됩니다. 특히 보안 솔루션과 고성능 DB가 공존하는 환경이라면, 보안 강화라는 목적이 서비스 가용성을 해치지 않도록 끊임없이 자원 간섭을 체크하고 정교하게 설정을 튜닝해 나가야 합니다.
[IBM Concert 솔루션 : AI 기반 IT 운영(AIOps)의 미래]